Character, Action, and Scene Customization & Long-Horizon Generation
Supports 3D character and scene assets from multiple sources (e.g., Hunyuan3D, Tripo, Meshy, Rodin, Sketchfab, World Labs Marble, ...).
Demo Video
Abstract
Recent advances in world models have greatly enhanced interactive environment simulation. Existing methods mainly fall into two categories: (1) static world generation models, which construct 3D environments without active agents, and (2) controllable-entity models, which allow a single entity to perform limited actions in an otherwise uncontrollable environment. In this work, we introduce CustomX, leveraging the realism and structural grounding of static world generation while extending controllable-entity models to support user-specified characters capable of performing open-ended actions. Users can provide a 3DGS scene and a character, then use natural language to direct the character to perform diverse behaviors, ranging from basic locomotion to object-centric interactions, while freely exploring the environment. CustomX synthesizes temporally coherent video clips that preserve visual fidelity with the provided scene and character, formulated as a conditional autoregressive video generation problem. Built upon a pre-trained video generator, our training strategy significantly enhances motion dynamics while maintaining generalization across actions and characters. Our evaluation covers a broad range of aspects, including visual quality, character consistency, action controllability, and long-horizon coherence.
Training & Inference Pipeline
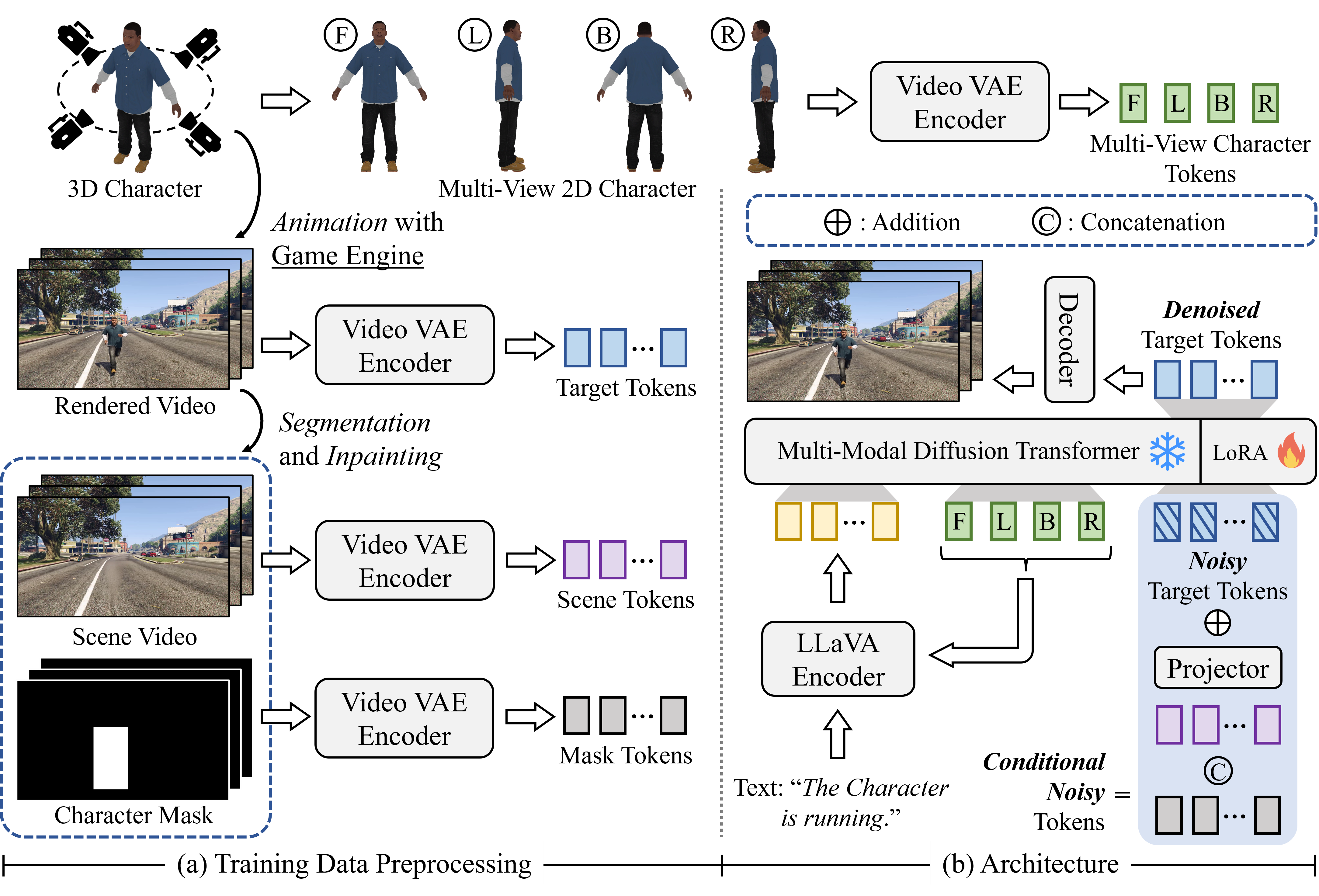
Training
(a) Each training sample consists of a 3D character and a video. Through segmentation and inpainting, we obtain scene videos and mask sequences.
(b) CustomX predicts target video tokens conditioned on scene, mask, text, and multi-view character tokens within a Multi-Modal Diffusion Transformer, trained using Flow Matching.
(c) CustomX is extended into an auto-regressive mode by introducing an extra conditioning input—the preceding video tokens, which supports multi-round user interaction and long-horizon generation while maintaining temporal continuity and semantic coherence between adjacent video clips.
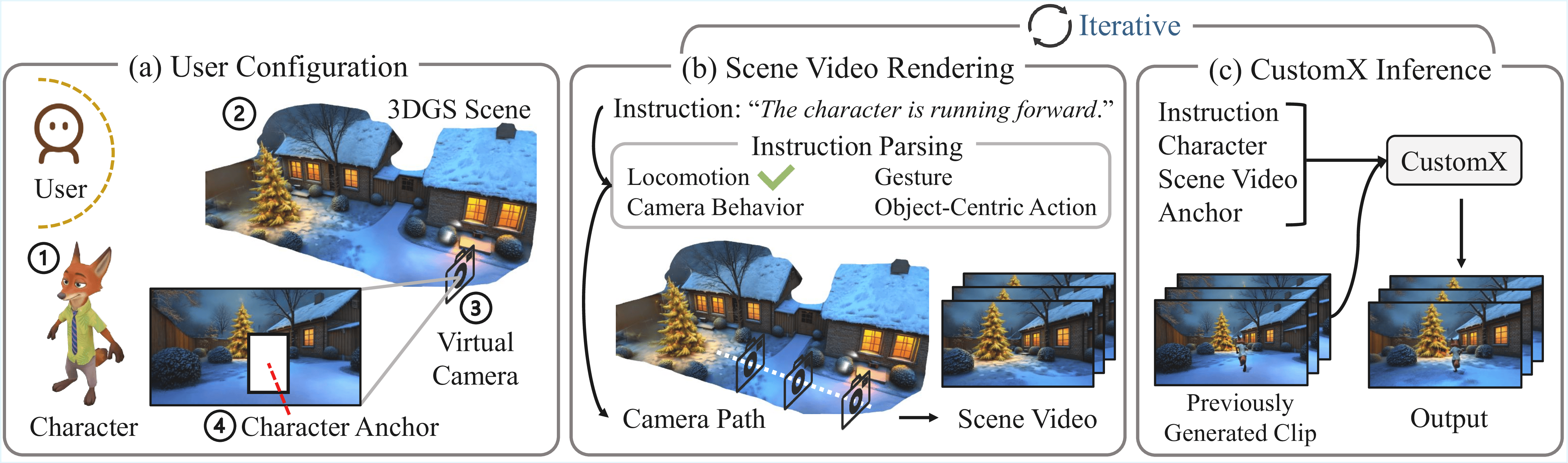
Inference
(a) Users first specify the inputs, including the character, 3DGS scene, virtual camera location, and character anchor.
(b) The user-provided text instruction is parsed, and a corresponding camera path is generated. Applying this path to the 3DGS scene produces a rendered scene video.
(c) CustomX then takes multiple inputs as conditions to generate the final output.
(d) Steps (b) and (c) can be performed iteratively, enabling temporally consistent, long-horizon interactions.
Video Results
Action Control and Generalization
CustomX generalizes to various novel actions beyond the training distribution while preserving character identity and scene consistency.
Clap hands.Dust with a feather duster.Play a harp.Box with gloves.Drink a bottle of juice.
Hold an umbrella.Exam clues with a magnifying glass.Eat a slice of pizza.Beat a drum with sticks.Weightlift with dumbbells.
Hold a cat.Hold a shield and sword.Wave a checkered flag.Mix colors on a palette.Play bagpipes.
Release a butterfly.Use a walkie-talkie.Play a flute.Play basketball.Draw a bow and arrow.
Use a laptop.Read a book.Swing a tennis racket.Hold a bunch of flowers.Pray with hands clasped.
Video Results
Character Customization
CustomX generalizes to previously unseen 3D characters from generation tools (e.g., Hunyuan3D, Tripo, Meshy, Rodin, ...) and online asset stores (e.g., Sketchfab, ...).
Pumpkin KnightInvisible Woman @ Marvel RivalsThe Destined One @ Black Myth: WukongSteampunk Cowboy
Robot CowboyBald Eagle ManIron MuskGreen-faced Youkai in Blue Sci-fi Armor
@misc{wang2026customx,
title={CustomX: Unified Character, Action, and Scene Customization in Video World Models},
author={Yitong Wang and Fangyun Wei and Hongyang Zhang and Bo Dai and Yan Lu},
year={2026},
eprint={2512.17796},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.17796},
}